M.E.L.T. - 4 Pillars of Observability

Before I come to what M.E.L.T. stands for, I must explain why.
“Why” is a question every programmer must have asked themselves when their code didn’t work when their production crashed or in general when they’re curious.
To answer this “why?” in every programmer’s life, Observability was coined.
Observability⌗

Observability involves gathering different types of data about all components within a system to establish the “Why?” rather than just the “What went wrong?”.
More formally, NewRelic defines it as; Observability is proactively collecting, visualising, and applying intelligence to all of your metrics, events, logs, and traces. So you can understand the behaviour of your complex digital system.
Observability is all about how well you can understand the system from the work it does. Just as a doctor makes a prescription noting down all the patient’s symptoms, something similar needs to be done for software.
How is this done? M.E.L.T.⌗
The acronym M.E.L.T. defines four essential data types for Observability: metrics, events, logs and traces.
Metrics⌗
The general definition states that “Metrics are measures of quantitative assessment commonly used for assessing, comparing, and tracking performance or production.”
To put it simply, metrics are numeric measurements. Metrics can include:
- A numeric status at a moment in time (like CPU % used)
- Aggregated measurements (like a count of events over a one-minute time or a rate of events-per-minute)
In an example of a car: A car shows metrics about its speed, engine rpm, temperature, tyre pressure etc.
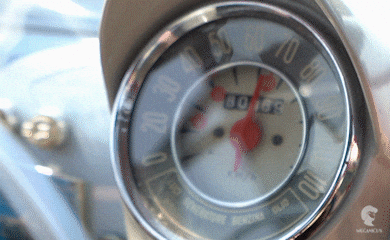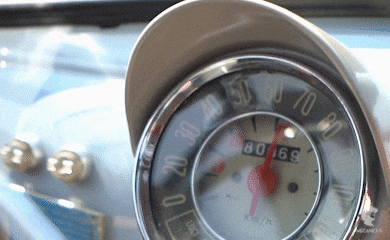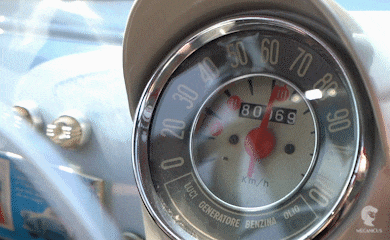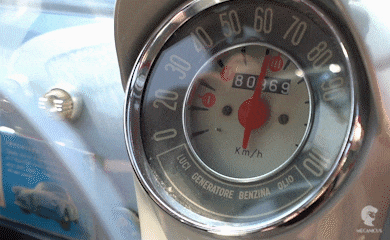
Events⌗
Conceptually, an event can be defined as an action happening at a moment in time. So, to start with our vending machine analogy, we could define an event to capture the moment when someone makes a purchase from the machine:
At 1825hrs on 12/21/2021, a bar of chocolate was purchased for ₹80 by userId 14432xxxx.
Events are valuable because you can use them to confirm that a particular action occurred at a specific time.
Because events are basically a history of every individual thing that happened in your system, you can roll them up into aggregates to answer more advanced questions on the fly.
Logs⌗
It’s not a stretch to say that logs are the O.G. data type.
In their most basic form, logs are essentially just lines of text a system produces when certain code blocks get executed.
Logs are granular, timestamped, complete and immutable records of application events.
Developers rely on them heavily to troubleshoot their code and retroactively verify and interrogate the code’s execution. In fact, logs are precious for troubleshooting databases, caches, load balancers, or older proprietary systems that aren’t friendly to in-process instrumentation, to name a few.
A log can look like this:
12/21/2021 1824hrs: 14432xxxx: Logged in
12/21/2021 1825hrs: 14432xxxx: Purchased 5423xx(bar of chocolate)
12/21/2021 1828hrs: 14432xxxx: payment completed for order: 9674xx
Alternatively they might also look like:

Logs are incredibly versatile, and most software systems can emit log data. The most common use case for logs is for getting a detailed, play-by-play record of what happened at a particular time.
Traces⌗
Traces record the end-to-end ‘journey’ of every user request, from the U.I. or mobile app through the entire distributed architecture and back to the user.
Distributed tracing is the best way to quickly understand what happens to requests as they transit through the microservices that make up your distributed applications.
Distributed tracing starts with instrumenting your environment to enable data collection and correlation across the entire distributed system. After the data is collected, correlated, and analysed, you can visualise it to see service dependencies, performance, and anomalous events such as errors or unusual latency.
Traces can look like this:

Why is Observability important?⌗
Modern-day architectures are turning big, complex and fast-paced. They’re being developed and deployed faster than ever—by distributed teams. With DevOps, continuous delivery, and agile development, the whole software delivery process is faster than ever before, making it more difficult to detect issues when they arise.
To make these systems secure, Observability is key in analysing the defects in the system.
Conventional monitoring won’t help us succeed in the complex world of microservices and distributed systems. It can only track known unknowns. These are the things you know to ask about in advance (for example: “What’s my application’s throughput?”, “What does compute capacity look like?”, “Alert me when I exceed a specific error budget.”)
Observability gives you the power to not just know that something is wrong…but also understand “why”. It gives you the flexibility to understand patterns you hadn’t even thought about before, the unknown unknowns.
Save your systems by M.E.L.T.(ing) them⌗
Okay, sorry for the bad pun. Bye Bye!